Build the Control Plane. Keep the Agent Disposable.
The strategic work in enterprise agentic AI is not a smarter agent. It is the deterministic state, identity, policy, and evidence the agent must never own — and the decisions that matter most are the ones you cannot reverse.
Most agent demos now work. The model reads the ticket, summarises the incident, suggests a fix, drafts the update, and — if you let it — calls the API that closes the loop. It is genuinely impressive, and it is also the least informative part of the whole exercise. The demo proves the agent can act. It says nothing about who owns the work once the agent is one of forty running in production, and that is the only question that scales.
The thing that is actually accumulating
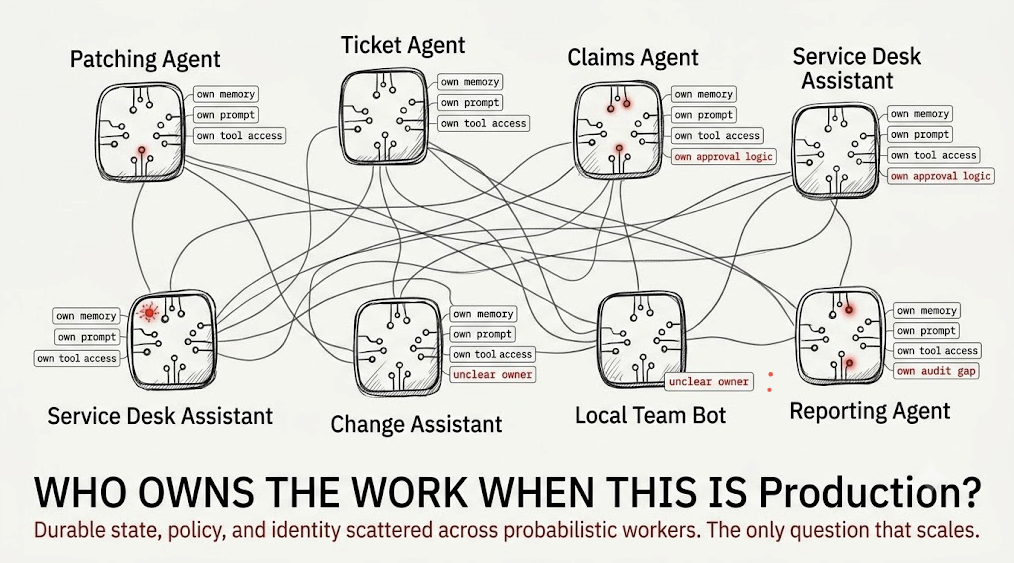
Walk into an organisation six months into its agent programme and the symptom is not failure. It is sprawl that looks like progress.
There is a “patching agent” with its own memory, its own approval logic, and its own integration into the change system. There are five tools that all create a ticket, written by five teams, none of whom own the other four. There are a few dozen assistants spun up locally, each useful, none inventoried. Every one of them demos well. Together they are a liability nobody has priced, because the thing each team built and now owns is the agent — and the agent is the wrong unit to build, own, or reuse.
That is the pattern underneath almost every agentic programme I look at. Control, state, and authority have quietly drifted into the one component that is probabilistic, opaque, and replaceable. The durable parts of the system — the record of work, the identity that acts, the policy that constrains it, the evidence that it happened — have been left implicit, scattered across prompt text and memory and whatever the model happened to retrieve.
I am less worried about agents being unreliable than about reliable agents accelerating an operating model nobody can see.
Why sensible teams build it backwards
This does not happen because people are careless. It happens because of an asymmetry that the current market narrative makes worse.
Building an agent is cheap, fast, and visible. It demos on a Friday. Building the plane around it — durable state, scoped identity, a policy engine, a capability registry, evaluation gates, an audit trail, lifecycle management — is expensive, slow, and invisible. It never demos, because its entire job is to be the part you do not notice until something goes wrong. So budget and attention flow to the component that shows well, and the component that determines whether any of it can actually be operated gets deferred to “phase two.”
Then “autonomy” is sold as the goal, which points the remaining effort in exactly the wrong direction. The implicit promise is that a sufficiently capable agent makes the surrounding discipline unnecessary. It is the reverse. The more an agent can do, the more it matters where the boundaries around it are drawn.
The popular fixes make it worse
This is where the usual story breaks. Faced with the limits of a single agent, the instinct is to reach for more of the same thing: more agents, more autonomy, multi-agent “intelligence,” an agent marketplace.
None of these address where control and state live, so none of them fix the underlying problem — and most amplify it. Multi-agent architectures add coordination cost and conflicting writes faster than they add capability. Picture two agents responding to the same production incident — one decides to restart the failing service, the other to roll back the last deployment — and each is right from where it sits. Now a restart is fighting a rollback on the same node, the outage is worse than the alert that triggered it, and neither agent did anything wrong. That is a conflicting write, and it is the normal failure of multi-agent systems, not a corner case. They earn their place on parallel, read-heavy work — five agents triaging five unrelated alerts at once — and become dangerous the moment two of them can act on the same system. Marketplaces without governance accelerate sprawl by design. “Autonomy” marketed as the absence of guardrails is not a capability; it is an unmanaged blast radius with a confident interface.
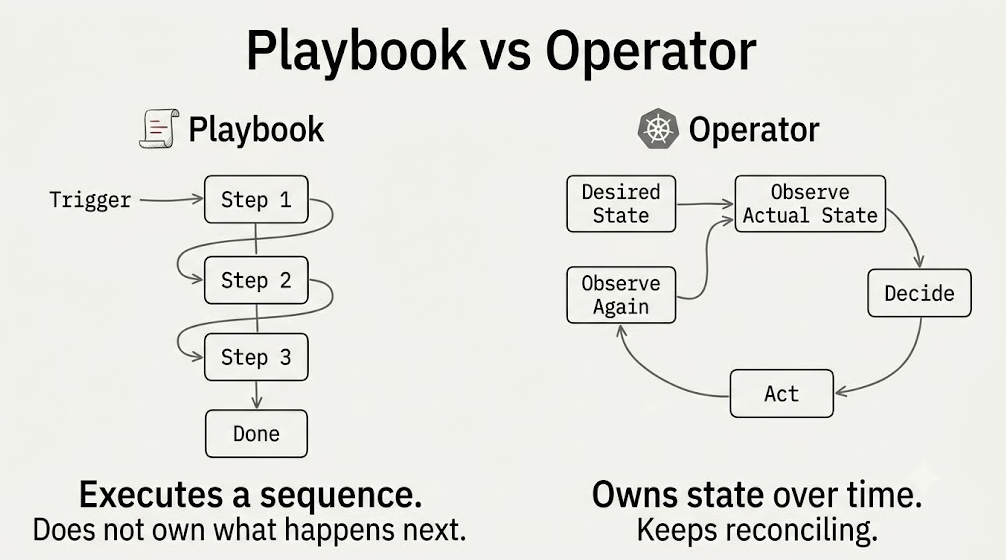
There is a useful distinction hiding in how IT teams already automate. A set of Ansible playbooks runs top to bottom, makes the changes you scripted, and finishes — it did the work, but it carries no standing responsibility for what happens next. If the thing it configured drifts an hour later, the playbook neither knows nor cares. An operator — the pattern Kubernetes made familiar — is the opposite: a long-running controller that owns a component, watches its real state against the state it is meant to be in, and keeps acting until the two agree. The playbook is a sequence of steps. The operator is an accountable owner with a control loop.
That is the line the agentic controller should sit on, and most agent programmes sit on the wrong side of it. The failure pattern is an agent built like a playbook with delegated authority: it runs its sequence — diagnose, decide, act, update the ticket — owns the whole thing while it does, and then forgets. The better pattern is a controller that behaves like an operator: it owns the work object, drives the incident or change toward closure, and calls on the agent only to propose the next step.
The operator instinct is right; taking it literally is not. A Kubernetes operator reconciles bounded infrastructure with a deterministic controller. An agentic controller reconciles service records, human approvals, and live production systems — and the moment a language model sits in the loop, the reconciler becomes probabilistic, while the desired state of a real service is often fuzzy and, worse, the actions are frequently irreversible. You cannot trust a model as a deterministic reconciler, and you cannot recall a configuration change once it has propagated to every node because the loop reconsidered.
So the answer is not an autonomous agent running a clever playbook. It is operator-like discipline — a deterministic control loop that owns the work object — with the agent demoted to a replaceable worker inside it.
What the better model actually is
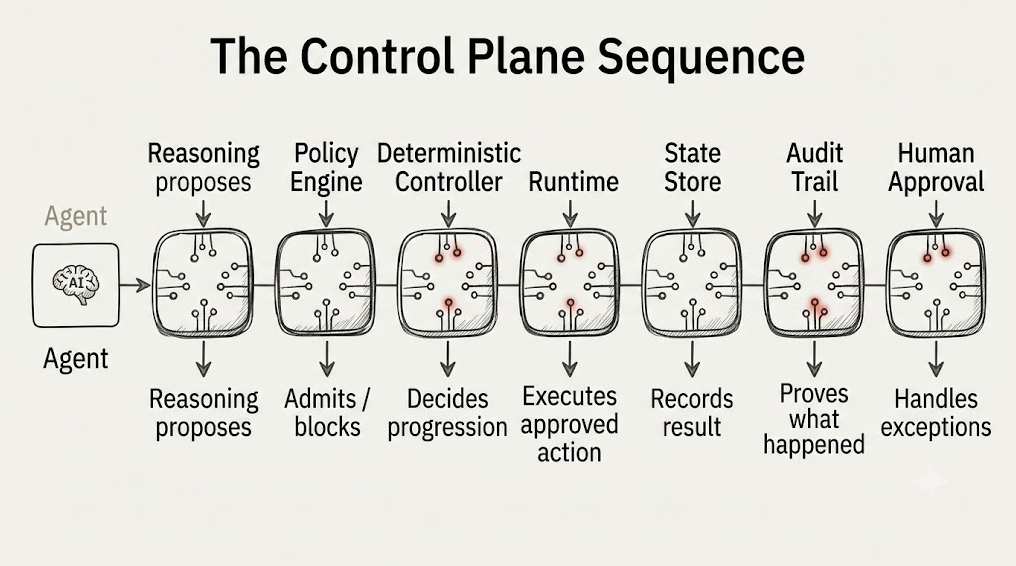
The separation that holds up in production is unglamorous and easy to state:
Reasoning proposes. Policy admits. A deterministic controller decides progression. The runtime executes. The state store records. Audit proves. Humans approve the exceptions.
Put a single incident through that line and it stops being abstract. An alert fires: a production service is returning errors. The model reads the alert and the recent telemetry and proposes an action — restart the service. A policy engine admits or blocks it: is a restart permitted on this tier, is the service inside a change-freeze window, does this customer’s contract allow automated remediation, is the blast radius within limits? A deterministic controller decides what happens next — run the remediation, page the on-call engineer, or gather more diagnostics — in plain code, not by asking the model a second time. The runtime executes by running the approved runbook automation exactly once. The state store records the action and its result on the incident record, so the next engineer who opens it sees an authoritative history, not a chat transcript. The audit trail proves it: which model proposed the action, which policy decision allowed it, which automation ran, which engineer approved. And above a severity threshold, a human approves the exception before anything touches production. The agent did exactly one thing in that sequence — it suggested a fix. Everything that touched the production system, the permissions, or the incident record was handled by something deterministic, owned, and logged.
The centre of gravity is the work object — the incident, the change request, the service request, the provisioning task — not the agent. The work object is durable, typed, and authoritative; it carries intent, constraints, status, and owner. The controller that advances it is deterministic and testable. The agent sits behind a governed boundary as a probabilistic worker: change the model that proposes the remediation next quarter, and the policy rules, the runbook automation, and the audit trail are all untouched. The reusable unit is the work object, the controller, the policy, the capability contract, and the audit surface. The agent is the part you throw away.
This is no longer a whiteboard argument, which is the genuinely new development. The cloud platforms are now shipping the plane as separable primitives rather than as one monolithic agent product. AWS Bedrock AgentCore reached general availability in October 2025 — runtime, memory, gateway, identity, and observability becoming separable platform primitives, designed to work with any framework and any model — with policy and evaluations following as generally available services in March 2026. The design statement embedded in that decomposition is the whole point: the runtime, the identity, and the audit are durable platform concerns; the agent is interchangeable.
Microsoft makes the same statement even more bluntly in identity. Microsoft’s 2026 documentation frames Entra Agent ID as treating agents as first-class non-human identities with their own lifecycle. The detail worth dwelling on is the sponsor: Microsoft requires every agent identity to name a human sponsor, accountable for the agent’s purpose and its lifecycle, with workflows that reassign that sponsorship when the person changes role — specifically so the organisation does not accumulate orphaned agents with live credentials and no owner. That single requirement is this entire article compressed. The platform is encoding the question “who is accountable when this agent acts?” directly into the identity model, because the agent itself can never answer it.
Inside that frame, the build-versus-buy line becomes clear rather than ideological. Standardise the things that must be consistent — and standardising them means something concrete. A capability contract is what ends the “five tools that all create a ticket” problem: one governed create-ticket capability, with an owner, a fixed schema, and a permission list, that every agent calls instead of each team quietly writing its own. Policy-as-code is the difference between the rule that an agent may restart a service in test but never touch production outside a maintenance window living in an engine that can veto the action, and the same rule written hopefully into a prompt where nothing actually enforces it. Evaluation gates are the test set a new model or prompt has to pass before it ships, so the upgrade that quietly starts mis-ranking incident severity never reaches the on-call queue. Keep flexible the things that should change often — which model you use, how you word the prompt, how you fetch context, what the screen looks like — because those are the parts you will tune every month. Buy the commodity substrate the market is now maturing — durable runtime, model and tool gateways, observability, identity integration, sandboxed execution. Build only what is irreducibly yours: the work object, the domain controller, the approval rules, and the compensating action for everything that cannot be undone.
One line in that list is easy to draw on a slide and brutal to build: the capability contract. Wrapping a modern API in a clean, typed, owned capability is a week of work. Doing it across a legacy estate — an ageing ITSM tool, a CMDB nobody fully trusts, a homegrown change system, and four monitoring stacks that each model an “incident” differently — is the actual programme. The hard part is not the agent calling the tool; it is agreeing what a “change” or an “incident” is across systems that have never agreed, and keeping those contracts faithful as the systems beneath them drift. A team that has not budgeted for that semantic-mapping tax has not budgeted for the project.
There is one trade-off here that is not symmetrical, and it is worth naming because it is where this advice fails if taken carelessly. Centralising the plane creates a real bottleneck risk. But a thin plane that teams actually adopt beats a thick one they route around, because partial adoption with inconsistent controls is precisely how you get the shadow agents you were trying to prevent. The failure mode of over-centralisation is slowness. The failure mode of under-adoption is loss of control. They are not equally bad.
“Thin” here means thin in what the plane dictates, not cheap to build. A plane teams will actually accept still needs a real policy engine, short-lived-credential identity, and an immutable audit trail — a multi-quarter programme with nothing that demos. That is the quiet reason most organisations never get a plane: next to another impressive agent, the credible version looks expensive and invisible, and loses the argument every time.
There is also a limit that no amount of your own platform work removes yet. Even with the plane built, the part the market has not solved is desired-versus-actual reconciliation over live production systems with safe, reversible side effects. Connectivity and identity are maturing quickly — the protocols that let agents reach tools and reach each other, and the IAM constructs that scope them, are real and improving. Work-object reconciliation and standardised compensation for irreversible actions are not. I would treat that as the frontier, not a solved problem, and I would be suspicious of any vendor claiming otherwise.
Questions for leaders
These are the questions worth asking before the next agent reaches production, not after.
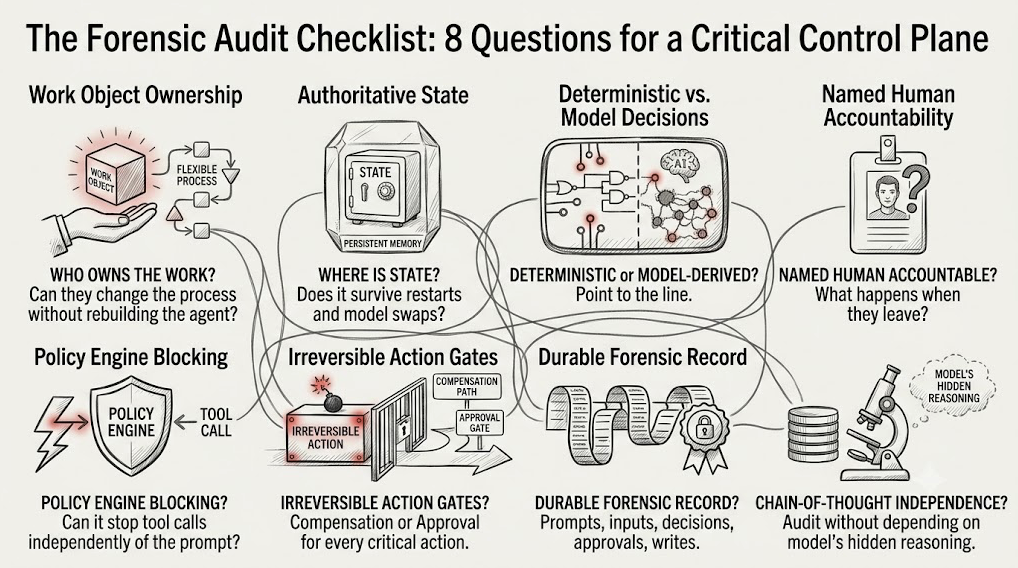
- Who owns the work object once the agent is live — and can that owner change the process without rebuilding the agent?
- Where does authoritative state live, and does it survive a restart and a model swap?
- Which decisions in this flow are deterministic, and which are model-derived? Can you point to the line?
- Is there a named human accountable for each agent in production — and what happens to that agent when they leave?
- Can the policy engine block a tool call independently of the model, or does the only guardrail live in the prompt?
- For every irreversible action, what is the compensation path or the approval gate?
- Can you reconstruct the full decision path from durable evidence — prompts, inputs, tool calls, model version, policy decisions, approvals, and record writes — without depending on the model’s hidden reasoning as an audit artifact?
That last one carries a specific position. Do not treat a model’s internal chain-of-thought as your forensic record. It is not stable, not reproducible, and not evidence. Log the decision path explicitly, or accept that you cannot explain your own system to an auditor.
Final thought
The question is not whether agents can do the work. They increasingly can, and that capability will keep improving without your help.
The question is whether you are willing to treat the agent as the disposable part — and to spend your scarce architecture effort on the state, identity, policy, and evidence it must never own. An organisation that builds a smarter agent on a weak plane has not bought control. It has built a faster, more confident way to lose it — and it will not see how until the work the agents have been doing turns out to belong to no one.
This article includes AI-assisted research synthesis. Sources were reviewed manually, and the interpretation is my own.
Comments